

主要是基于官网上的内容Apache-Hadoop-3.2进行总结,熟悉整体架构。
Hadoop是以HDFS (Hadoop Distributed File System) 分布式文件系统存储文件,MapReduce提供计算框架。
整体架构基于Google的GFS, MapReduce, BigTable. 进一步深入学习可以参照MIT6.824。
目录
HDFS
HDFS是一款分布式文件系统,具有高容错,部署在低成本硬件。HDFS提供但堆应用数据的高吞吐。
Assumptions and Goals
- Hardware Failure: 节点出错是不可避免的,因此需要快速的检测,自动恢复。
- Streaming Data Access: HDFS的数据设计为批量处理而不是与用户交互,强调高吞吐而不是低延迟。
- Large Data Sets
- Simple Coherency Model: HDFS的应用需要一个写一次,读多次的文件模型。除了追加和截断,不允许修改,追加只能在末尾。这假设简化了数据一致性问题,而且实现了高吞吐。
- Moving Computation is Cheaper than Moving Data:因为局部性,当数据存储邻近时,计算会更有效率,HDFS通常是迁移计算。
- Portability Across Heterogeneous Hardware and Software Platforms:为什么能被广泛应用的原因。
NameNode and DataNodes
HDFS的架构如下:
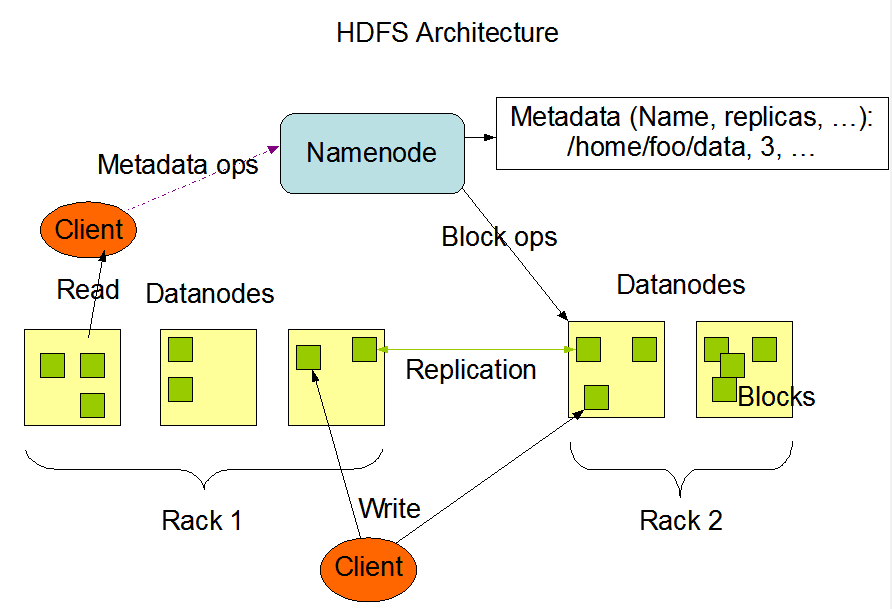
是一个主从体系,一个集群由一个NameNode, 管理文件系统命名空间以及管理用户访问文件的主服务器,以及多个DataNodes。
- NameNode: 负责打开,关闭,重命名,目录以及映射到DataNodes。
- DataNode: 负责读,写,块的创造,删除,复制。
Data Replication
HDFS设计为在大集群上可靠性高得大型文件存储,将每个文件存储城一系列的文件块(通常128MB)。这些块除了最后一个都是同样大小。
为了容错率,这些块需要复制,赘余存储在不同的DataNode中,NameNode做出所有关于复制的决定。NameNode定期的从DataNode接收Heartbeat(检测DataNode是否正常运行)和Blockreport(DataNode上包含的块的列表)。
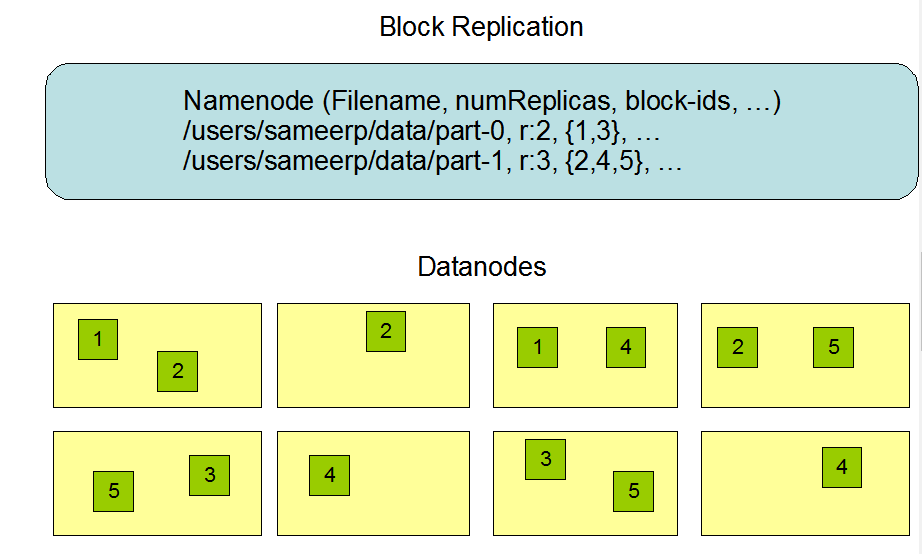
replicate placement
HDFS的文件放置策略在权衡数据可靠性,可用性,网络带宽的利用性。
通常情况下,复制因子为3,在写入的DataNode里有一份,同一机架另一个DataNode有一份,不同机架里的随机DataNode有一份。该策略减少了机架间的写流量,通常可以提高写性能。机架故障的机会远少于节点故障的机会,因此不会影响数据的可靠性和可用性保证。但是,由于一个块仅放置在两个唯一的机架中,而不是三个,因此它确实减少了读取数据时使用的总网络带宽。使用此策略,文件的副本不会在机架上均匀分布。三分之一的副本位于一个节点上,三分之二的副本位于一个机架上,其余三分之一则平均分布在其余机架上。此策略可提高写入性能,而不会影响数据可靠性或读取性能。
Robustness
HDFS的主要目标是即使出现故障也能可靠地存储数据。三种常见的故障类型是NameNode故障,DataNode故障和网络分区故障。
下面是一些支持HDFS鲁棒性的措施:
- Data Disk Failure, Heartbeats and Re-Replication
- Cluster Rebalancing
- Data Integrity
- Metadata Disk Failure:HDFS support maintaining multiple copies of the FsImage and EditLog.
- Snapshots: Snapshots support storing a copy of data at a particular instant of time. One usage of the snapshot feature may be to roll back a corrupted HDFS instance to a previously known good point in time.
MapReduce
Hadoop MapReduce是一个软件框架,用于编写应用程序,以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(TB数据集)。
MapReduce通常将输入数据集拆分为独立的块,以完全并行的方式进行map。然后对map的输出进行排序,然后将其输入到reduce。通常,作业的输入和输出都存储在文件系统中。MapReduce负责安排任务,监视任务并重新执行失败的任务。
通常来说,计算节点和存储节点都是相同的,MapReduce框架和HDFS跑在相同的节点上,这样运行MapReduce高效的安排任务。
Inputs and Outputs
MapReduce 仅对键值对<key, value>进行操作,输入输出都是键值对。
YARN
YARN的基本思想是将资源管理和作业调度分成分离的程序。
YARN架构如下:
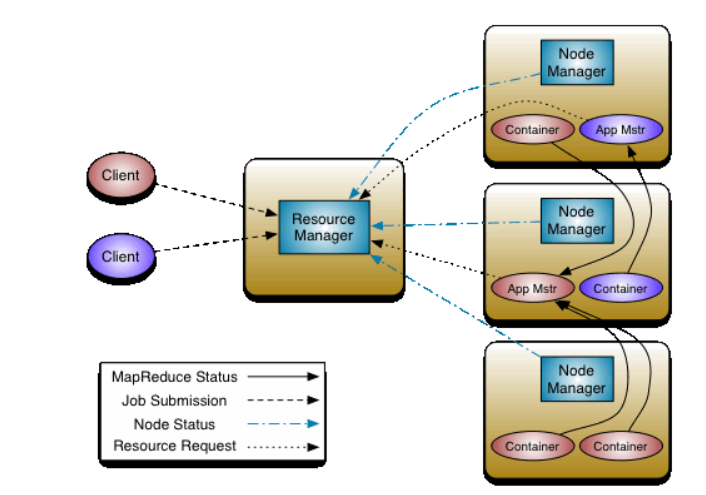
ResourceManager 和 NodeManager 来自数据计算框架。ResourceManager 是系统中所有资源的最终权限。NodeManger 是每台机器框架代理,负责容器,见识资源使用状况,并报告给ResourceManager.
每个 Application Master 是每个应用程序基于框架的特别的库,任务是与ResourceManager 协商与NodeManager执行和监管任务。
ResourceManager由两个主要组成:Scheduler and ApplicationsManager.
- Schedule:负责将资源分配给各种正在运行的应用程序,但要遵循熟悉的容量,队列等约束。调度程序根据应用程序的资源需求执行调度功能;它基于资源容器的抽象概念来做到这一点,该容器包含诸如内存,cpu,磁盘,网络等元素。
- ApplicationsManager:负责接受作业提交,协商用于执行特定于应用程序的ApplicationMaster的第一个容器,并提供在发生故障时重新启动ApplicationMaster容器的服务。


- 本文作者: SFARL
- 本文链接: sfarl.github.io/2020/12/01/Hadoop/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
 Desmond's blog
Desmond's blog